Scripting in C##
This guide documents the way you can develop user tasks for KAPPA-Automate using C# language.
User task is intended to process X inputs and populate Y gauges, optionally storing its internal parameters and state in the context. User task code is executed in a specific restricted environment and the following services/data are accessible:
Parametersobject is a container of input and output dictionaries that provide your user task with named input and output values. The following parameter types are supported:Dataset(the id of the vector that holds the gauge data)File(the id of the uploaded file)stringDateTimeDateTimeOffsetintdoublebool
Contextobject is astring-key dictionary that allows you to persist values of any serializable data type between the user task executions.DataEnumeratorservice allows you to access data of n gauges using a common time index.IDataQueryServiceservice allows you to query data of a single gauge.IDataCommandServiceservice allows you to write data to the output gauges.IEventPublisherservice allows you to publish events related to your user task.FileServiceservice allows you to access files that were uploaded to KAPPA-Automate.RestGatewayservice allows you to access different KAPPA-Automate services via REST API.
Note
The following limitations apply to the C#-based user tasks at the moment:
User tasks are using C# language specification 7.3.
It is not possible to define nested classes (but it is possible to define local functions).
It is not possible to load external DLL or access any libraries except the ones provided.
Parameters#
All the script parameters are accessible through the Parameters object and are identified by their name (which are case sensitive). This Parameters property exposes the following properties:
public DictionaryWrapper In {get;}
public OutDictionaryWrapper Out {get;}
In property wraps all input parameters, while Out property wraps all output parameters.
DictionaryWrapper object exposes the following methods:
public T Value<T>(string parameterName)
public bool TryGetValue<T>(string parameterName, out T value)
OutDictionaryWrapper object exposes the following methods (note the additional method that allows to write values for the output parameters:
public T Value<T>(string parameterName)
public bool TryGetValue<T>(string parameterName, out T value)
public void Write<T>(string parameterName, T value)
Note
The type of T is limited to the following types:
bool
Dataset
DateTime,
DateTimeOffset
double
File
int
string
The following example demonstrates how to read the values of the input parameters:
var gasGaugeDataset = Parameters.In.Value<Dataset>("Gas Gauge")
var oilGaugeDataset = Parameters.In.Value<Dataset>("Oil Gauge")
var removeNan = Parameters.In.Value<bool>("Remove NaN")
var gorGaugeDataset = Parameters.In.Value<bool>("GOR Gauge")
Context#
As the name implies, the Context object gives you access to the context of the user task.
This context is saved at the end of the execution of the user task and is restored for the next execution.
This way, it gives you the ability to know the state of the previous execution.
By default, this context is empty, but you can define and store in it any serializable values via string-key based dictionary:
public void Write(string key, object value)
public T Read<T>(string key)
public T[] ReadArray<T>(string key)
The following example demonstrates how to read and write an integer value with the context:
var lastOutput = Context.Read<int>("IncrementingValue")
Context.Write("IncrementingValue", lastOuput + 1)
Data Enumerator#
The simplest way to read vector data from inputs is to use the DataEnumerator. It is able to create a single enumeration from any numbers of input datasets.
The resulting X range is by default the union of all inputs and the Y values are either the real value or the closest one (linear interpolation).
The enumerator is optimizedand it will read slices of data by chunks.
The following methods are accessible:
public IEnumerable<DataProductPoint> ToEnumerable(params Dataset[] vectors)
public IEnumerable<DataProductPoint> ToEnumerable(DateTimeOffset from, params Dataset[] vectors)
public IEnumerable<DataProductPoint> ToEnumerable(DataProductSettings settings, params Dataset[] vectors)
The first method is used to enumerate values of provided datasets from the beginning of each vector. The second method lets you specify the start of the enumeration and the last one allows you to perform an enumeration using specific settings:
public class DataProductSettings
{
public DataProductSettings(DateRange dateRange,
AbsentDataTreatment interpolationType,
ExtrapolationMethod extrapolationType,
int readChunkSize)
{
DateRange = dateRange;
InterpolationType = interpolationType;
ExtrapolationType = extrapolationType;
ReadChunkSize = readChunkSize;
}
public DateRange DateRange { get; }
public AbsentDataTreatment InterpolationType { get; }
public ExtrapolationMethod ExtrapolationType { get; }
public int ReadChunkSize { get; }
}
DateRange parameter allows to specify the exact start and end dates for the enumeration:
public class DateRange
{
public DateRange(DateTimeOffset exclusiveStart, DateTimeOffset inclusiveEnd)
{
ExclusiveStart = exclusiveStart;
InclusiveEnd = inclusiveEnd;
}
public DateTimeOffset ExclusiveStart { get; }
public DateTimeOffset InclusiveEnd { get; }
}
InterpolationType specifies the type of interpolation to use:
public enum AbsentDataTreatment
{
AbsentValue,
Zero,
PreviousValue,
NextValue,
AverageValue,
LinearInterpolation
}
ExtrapolationType specifies the type of extrapolation to use:
public enum ExtrapolationMethod
{
Zero,
AbsentValue,
BoundaryValue,
UseSlope
}
ReadChunkSize specifies the size of the chunk that is used to read the data.
Note
Large data (vs time or vs depth) are stored in the Cassandra database and are organized as:
Vector of actual data values - either the raw data, or a preview data (as a simple decimation of the raw data)
Associated metadata (e.g. count of data points, min/max X/Y, etc.)
You must take care of the identifiers used by these methods (vector id), as they are different from the ones used to identify the object in the field hierarchy (data id).
Usually, these identifiers are defined in property names like xyVectorId when receiving JSON-serialized data from services.
datasets are defined in points or stepsand values are always expressed in SI units. When dealing with step data, please note that values are always defined at the end of the step. The first value of the data set (i.e. the beginning of the first step) is defined in the metadata.
Data Query Service#
The IDataQueryService service gives you access to a set of methods to read a data vector from the Cassandra database.
Contrary to the DataEnumerator service, you have to manage the way you read data by chunks yourselfand you can only deal with a single data-set at a time.
public interface IDataQueryService : ISingletonService
{
XYVector ReadRaw(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
XYVector ReadPreview(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
XYVector ReadLast(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
VectorInfo GetInfo(Guid dataId);
double GetDtMin(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
int GetEligibleCount(Guid dataId,
DateTimeOffset? minX = null,
double? minY = null,
double? maxY = null,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
Task<VectorInfo> GetVectorInfoAsync(Guid dataId);
Task<XYVector> ReadRawAsync(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
Task<XYVector> ReadPreviewAsync(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
Task<XYVector> ReadLastAsync(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
Task<double> GetDtMinAsync(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
Task<int> GetEligibleCountAsync(Guid dataId,
DateTimeOffset? minX = null,
double? minY = null,
double? maxY = null,
DateTimeOffset? from = null,
DateTimeOffset? to = null,
int? count = null);
}
The definition of the XYVector is as follows:
public sealed class XYVector
{
public XYVector(IList<DateTimeOffset> x, IList<double> y)
{
X = x;
Y = y;
}
public IList<DateTimeOffset> X { get; }
public IList<double> Y { get; }
}
VectorInfo is used to store the vector metadata:
public sealed class VectorInfo
{
public string Name { get; set; }
public string UserMeasureId { get; set; } = default(UserMeasureKey).ToString();
public bool IsByStep { get; set; }
public DateTimeOffset? FirstX { get; set; }
public int Count { get; set; }
public DateTimeOffset MinX { get; set; } = DateTimeOffset.MaxValue;
public DateTimeOffset MaxX { get; set; } = DateTimeOffset.MinValue;
public double MinY { get; set; } = double.MaxValue;
public double MaxY { get; set; } = double.MinValue;
public Guid FieldId {get; set;}
}
Data Command Service#
The IDataCommandService service gives you access to a set of methods to write data vector into the Cassandra database.
public interface IDataCommandService : ISingletonService
{
Guid Create(XYVector xyVector, VectorCreationInfo creationInfo);
void Delete(Guid dataId);
void AddValues(Guid dataId,
XYVector xyVector,
MetadataUpdateDto info = null);
void RemoveRange(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null);
Task<Guid> CreateAsync(XYVector xyVector,
VectorCreationInfo info);
Task<IEnumerable<Guid>> CreateManyAsync(IEnumerable<XYVectorAndCreationInfo> creationInfo);
Task DeleteAsync(Guid dataId);
Task AddValuesAsync(Guid dataId,
XYVector xyVector,
MetadataUpdateDto info = null);
Task RemoveRangeAsync(Guid dataId,
DateTimeOffset? from = null,
DateTimeOffset? to = null);
Task UpdateMetadata(Guid dataId, MetadataUpdateDto metadata);
}
When adding new data, you can also update the associated metadata: this is particularly important when dealing with the by step vectors
as you must provide the first point of the data set to define the duration of the first step. MetadataUpdateDto is used to pass the updated metadata:
public sealed class MetadataUpdateDto
{
public Optional<string> Name { get; set; }
public Optional<string> UserMeasureId { get; set; }
public Optional<bool> IsByStep { get; set; }
public Optional<DateTimeOffset?> FirstX { get; set; }
}
Normally, there is no need to use the Create method because any data-set defined as an output of a user task is created automatically. For reference, the definition of the VectorCreationInfo is as follows:
public sealed class VectorCreationInfo
{
public string Name { get; set; }
public string UserMeasureId { get; set; } = default(UserMeasureKey).ToString();
public bool IsByStep { get; set; }
public DateTimeOffset? FirstX { get; set; }
public Guid FieldId {get;set;}
public static VectorCreationInfo ByPoint(Guid fieldId,
string name,
string userMeasureId);
public static VectorCreationInfo ByPoint(Guid fieldId,
string name,
UserMeasureKey userMeasureId);
public static VectorCreationInfo ByStep(Guid fieldId,
string name,
string userMeasureId,
DateTimeOffset? firstX);
public static VectorCreationInfo ByStep(Guid fieldId,
string name,
UserMeasureKey userMeasureId,
DateTimeOffset? firstX);
}
Event Publisher Service#
This IEventPublisher service gives you access to a facility to publish events.
The topic of the event is defined on the main property page of the user task.
When publishing an event, you can define a range of dates (e.g. the validity of a shut-in event) and a payload.
public async Task PublishAsync(DateTimeOffset? from, DateTimeOffset? to, object eventContent);
The following example illustrates publishing of an event in the GOR calculation user task which is raised when the GOR value exceeds some threshold:
await IEventPublisher.PublishAsync(lastDate, date, new double[] { gasOilRatio });
FileService#
The FileService service allows you to download and read the content of a file which was defined as an input parameter of type File:
public interface IFileService
{
DownloadResult DownloadFile(File file);
byte[] GetContent(File file);
Task<DownloadResult> DownloadFileAsync(File file);
Task<byte[]> GetContentAsync(File file);
}
RestGateway#
The RestGateway service gives you the ability to consume any REST API exposed by KAPPA-Automate:
public interface IRestGatewayWrapper
{
Task<HttpResponseMessage> Get(
string serviceName,
string route);
Task<HttpResponseMessage> Post<T>(
string serviceName,
string route,
T objectDto);
Task<HttpResponseMessage> Put<T>(
string serviceName,
string route,
T objectDto);
Task<HttpResponseMessage> Delete(
string serviceName,
string route);
}
The list of valid service names is as follows:
Field
Filtering
ExternalData
Automation
KWaaS
Processing
EventStore
Computing
You can find information about the route parameters in the API documentation of each service e.g.
/v1/field/allfor fetching the list of all fields/v1/field/{field id}/well/{well id}for getting access to the specific well
Hint
You can use string as a T type parameter to pass your request parameter object as a JSON-serialized string.
C# GOR User Task Sample#
You can find a complete sample for GOR calculation in C# below:
Inputs Definition (YAML)
inputs:
GasGauge:
type: dataset
mandatory: true
dimension: GasRateSurface
isByStep: true
OilGauge:
type: dataset
mandatory: true
dimension: LiquidRateSurface
isByStep: true
Remove NaN:
type: boolean
mandatory: true
currentValue: true
outputs:
OutputGauge:
type: dataset
mandatory: true
dimension: GasLiquidRatio
isByStep: true
Dynamic inputs validation (JavaScript)
var gasDimension = yamlIn.inputs["GasGauge"].dimension;
var oilDimension = yamlIn.inputs["OilGauge"].dimension;
if(gasDimension !== "GasRateSurface")
{
throw new Error("Gas gauge dimension must be 'Gas Rate surface'");
}
if(oilDimension !== "LiquidRateSurface")
{
throw new Error("Oil gauge dimension must be 'Liguid Rate surface'");
}
User task script#
/////////////////////////////////////////////////////////////////////
//// Compute the Gas/Oil ratio of the two input gauges ////
/////////////////////////////////////////////////////////////////////
var inDataParam1 = Parameters.In.Value<Dataset>("GasGauge");
var inDataParam2 = Parameters.In.Value<Dataset>("OilGauge");
var removeNan = Parameters.In.Value<bool>(" Remove NaN ");
var outDataParam = Parameters.Out.Value<Dataset>("OutputGauge");
var datasetEnumerator = DataEnumerator.ToEnumerable(inDataParam1, inDataParam2);
XYVector outputVector = XYVector.Empty;
await IDataCommandService.UpdateMetadata(outDataParam.DataId,
new MetadataUpdateDto
{
FirstX = datasetEnumerator.First().Date
});
double gorEventLimit = 105;
DateTimeOffset? lastDate = null;
double lastValue = 0;
foreach(var point in datasetEnumerator.Skip(1))
{
double v1 = point.Values[0];
double v2 = point.Values[1];
var date = point.Date;
double gasOilRatio = v1 / (v2 == 0 ? double.NaN : v2); // Of course, strategy when value is null can be enhanced
if(removeNan && double.IsNaN(gasOilRatio))
{
if(lastValue == 0)
{
continue;
}
outputVector.Y.Add(lastValue);
}
else
{
outputVector.Y.Add(gasOilRatio);
lastValue = gasOilRatio;
}
outputVector.X.Add(date);
if(gasOilRatio > gorEventLimit)
{
await IEventPublisher.PublishAsync(lastDate, date, new double[]{gasOilRatio});
gorEventLimit += 1;
lastDate = date;
}
}
await IDataCommandService.RemoveRangeAsync(outDataParam);
await IDataCommandService.AddValuesAsync(outDataParam, outputVector);
REST API#
KAPPA-Automate platform is built around micro-services that expose a REST API that is accessible to external consumers. Internally, each service can be found at a specific port (and at a specific path externally)and the API for each service can be viewed and tested dynamically with the help of Swagger.
The figure below shows the complete list of services and their port numbers.
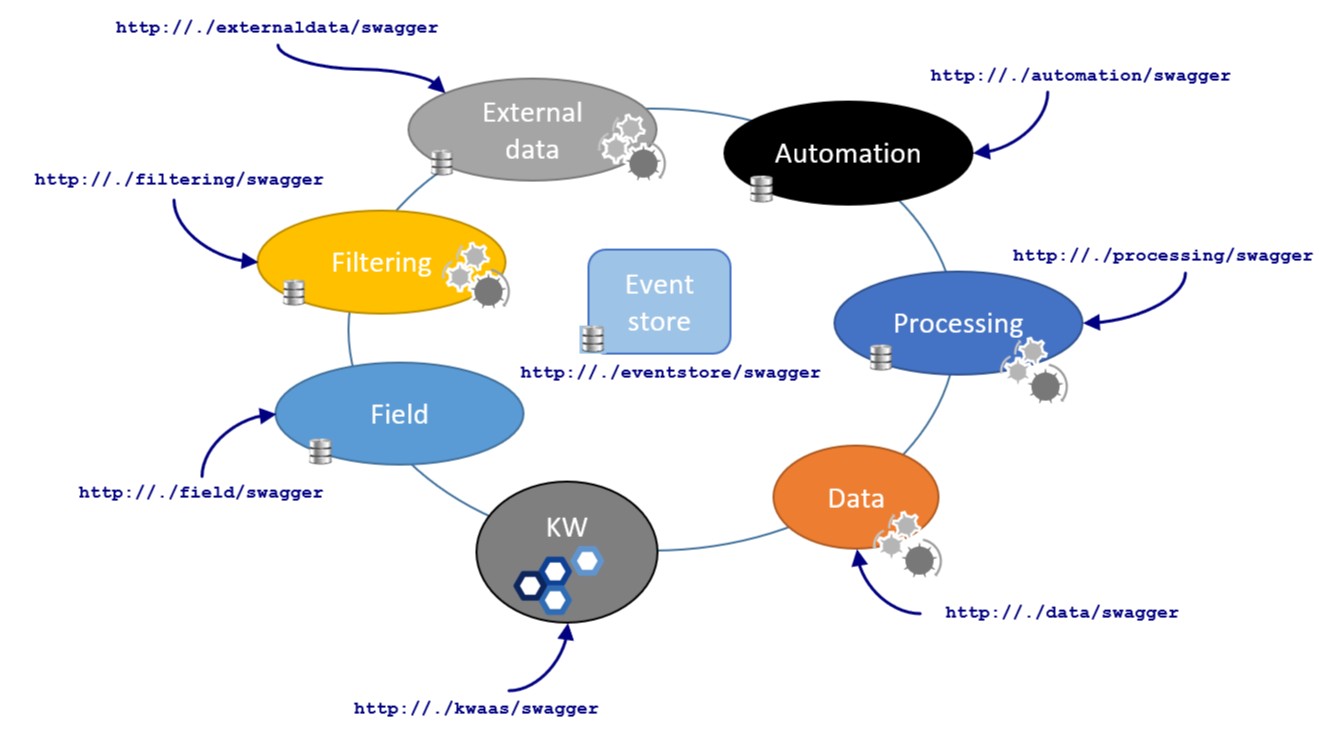
Fig. 1 Platform services and port numbers#
Fieldservice manages the field hierarchyDataservice handles time series and logsExternalDataservice provides access to external data-sourcesAutomationservice manages the job executionComputationservice deals with functionsProcessingservice deals with user tasksEventStoreservice manages the platform eventsKWservice provides APIs for Saphir and Topaze.
Note
Computation and Processing services will merge after v6.0.
Note
KW service will later be decoupled into distinct services per module.
To access the API via Swagger, you need to replace the . in the URLs shown in Fig. 1 with your server addressand point your web browser to this URL.
For instance, below is the list of methods offered by the Field service using the /field/swagger path:
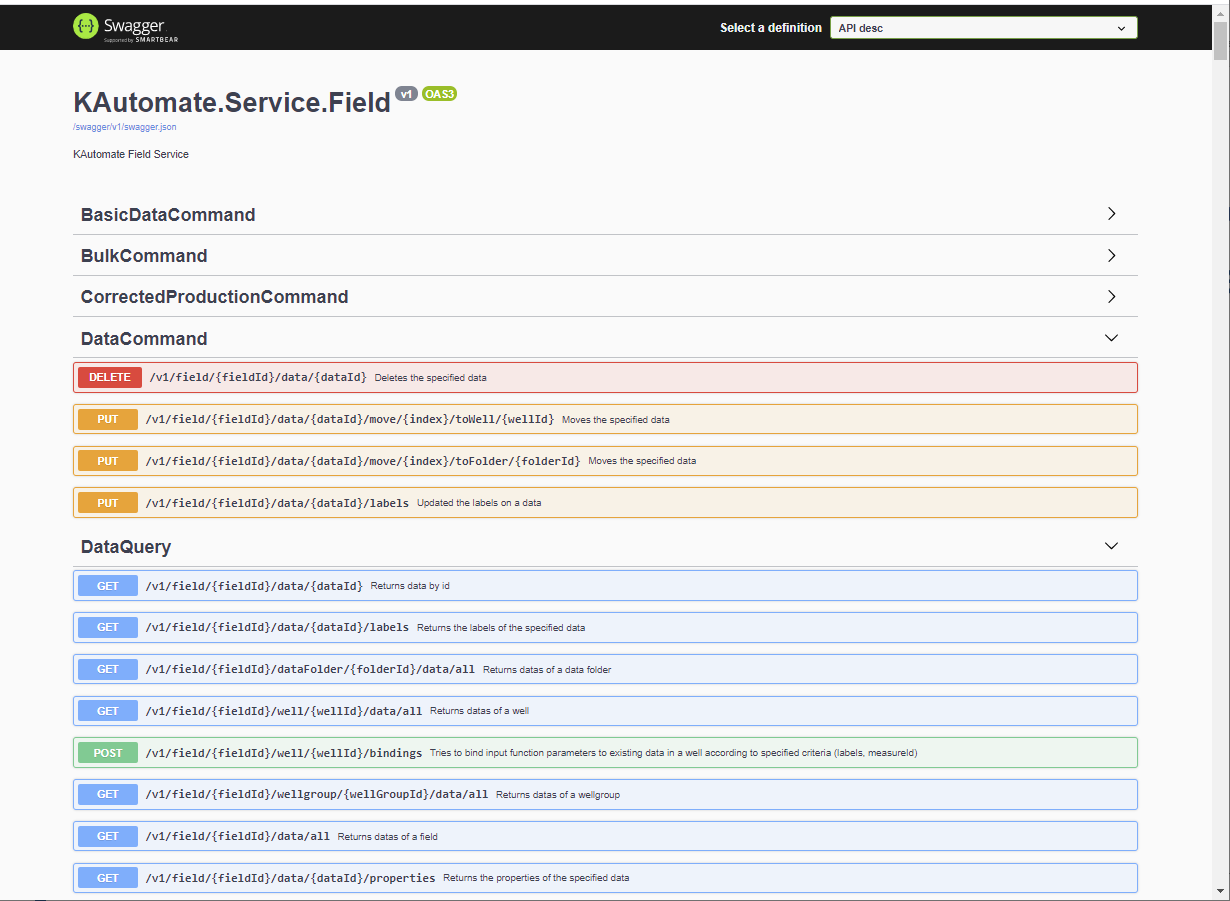
Fig. 2 User interface of Swagger#
The details of a method can be obtained by clicking on the corresponding line. See for instance the FieldCommand method which creates a new field:
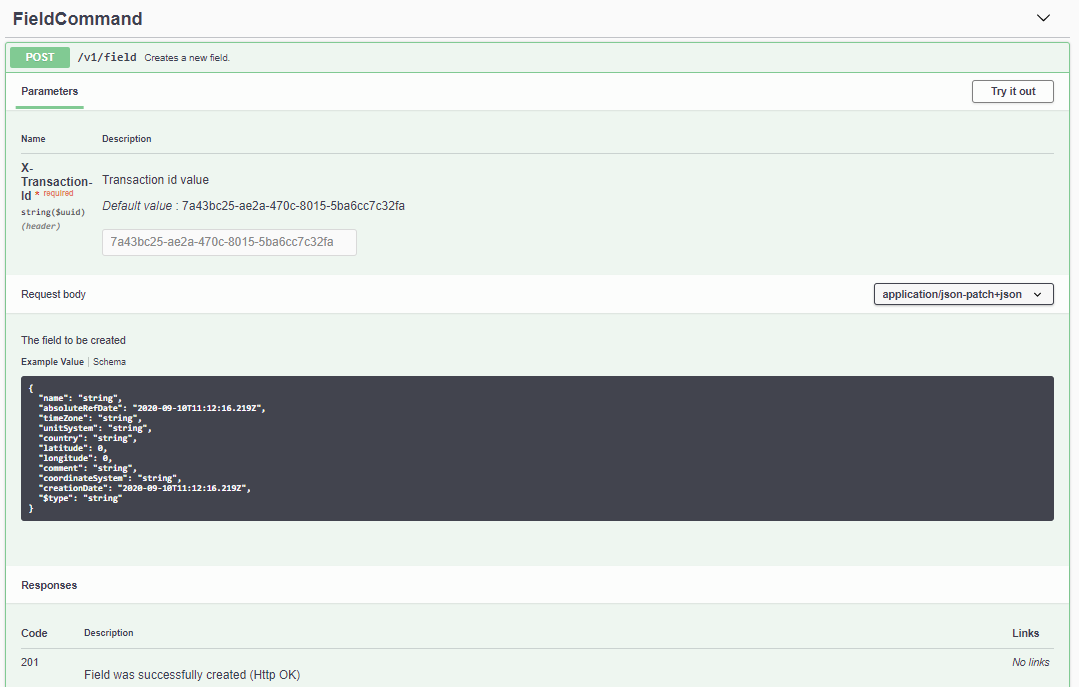
Fig. 3 User interface of Swagger for the “FieldCommand” method#
The details include the typical input as a JSON string or payload. This can be copied and modified in order to experiment with the method.
To do so, you need to click on the Try it out button, paste or type the inputsand then click on the Execute button.
Therefore, if you have access to these internal TCP ports, you can directly use this API from an external application. For instance, you could use http://yourDomain:12000/v1/field/all for the list of fields or http://yourDomain:12000/v1/field/{field id}/well/{well id} to get access to a specific well.
When you do not have access to these TCP ports (because of security restrictions), you cannot directly use the REST API provided by these services. You may also have restrictions to access RabbitMQ (message bus and events) and Cassandra for large data.
A possible solution is to use NGinx as an API gateway which gives you access to the complete platform through the TCP port 80. The same path as the one used by the Web UI can, therefore, be used.
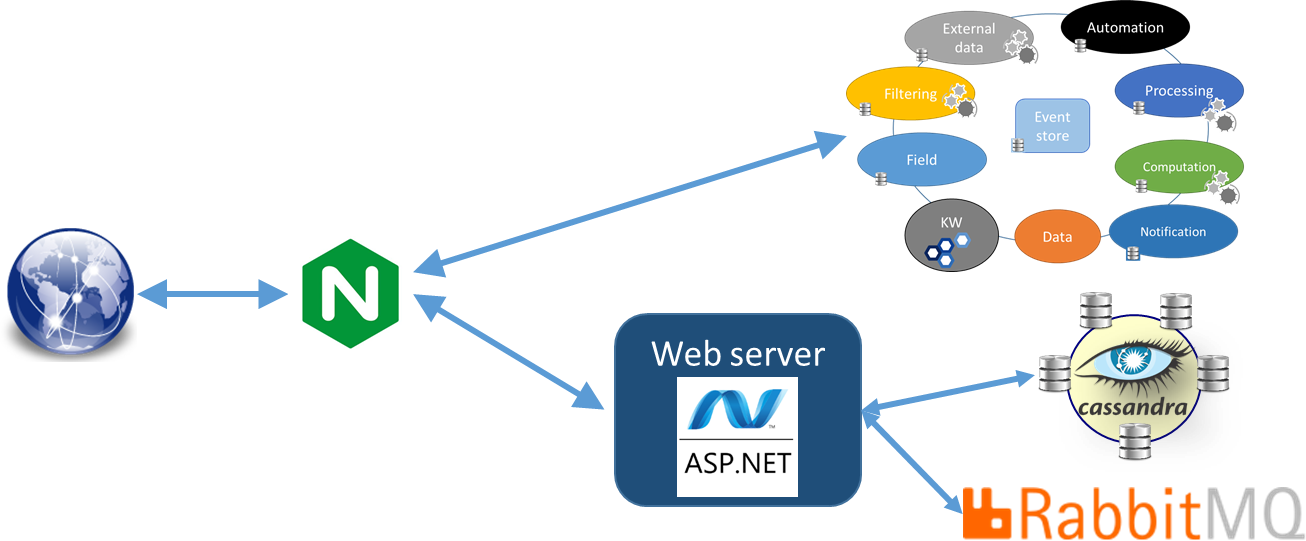
Fig. 4 Access to the KAPPA-Automate API through the NGinx-based proxy#
Specifically, a query is built this way: {root domain}/api/generic/get/{service}/{route} where:
{root domain}is the main URL of KAPPA-Automate{service}is the name of the service, e.g. field{route}is the specific API that you want to use. This API is the one that is described in Swagger e.g. /v1/field/all for the list of fields or /v1/field/{field id}/well/{well id} to get access to a well.
For POST/PUT/DELETE commands, the path is: {root domain}/api/generic/{service}/{route}
For large data stored in the Cassandra database, specific routes are exposed:
GET {root domain}/{data id} with optional parameters to read a single data vector:
fromandto: range of UTC dates to use when readingcount: number of data to retrieve (max = 100K)isRawData: read raw data or the decimated preview (default)
GET {root domain}/info/{data id} to read data vector metadata
Note that for data creation/update/deletion you must use the first routes, e.g. {root domain}/{route}
Finally, the events and messages exchanged through the RabbitMq bus are exposed through the web sockets at the following address: {root domain}/signalr
Events and messages#
Any change in any service systematically triggers an event. It lets other services react to these events and by the same occasion, it creates workflows across services. For instance, user tasks and, obviously, external applications, can raise their own events. Conversely, once connected to the bus, an external application can subscribe to any kind of event. Events come with a context that gives all the necessary information, including the IDs of the hierarchy elements involved. For instance, you may subscribe to the update events on a particular dataset/datasets of a particular well.
A list of possible events and corresponding JSON payloads can be found in the Events Reference. Note that this is given as an example as the content of the events can evolve with time.