User task simulation#
The UI interface of Kappa-Automate is not designed for development. That is why we developed a “simulated environment” to simulate a user task execution from your local machine. It allows you to debug and test your user task code locally on your development machine before deploying it to the KAPPA-Automate server.
When implementing a new user task you will need at least the following three project files to run this user task locally. It is essential that the naming between those three files matches. When running the simulation (locally executing your user task), it will search for the user task code file and input/output definition file by their names:
<your_user_task_name>_simulation.pyIt will contain code that performs parameters binding - that, in a real KAPPA-Automate environment, happens in theCreate a new user taskdialog when creating a new user task instance in the well. You will execute this file to execute your user task in simulation mode.As you can see in the 2 next images we bind the inputs of the user task: Gas Rate, Oil Rate and Remove NaN.
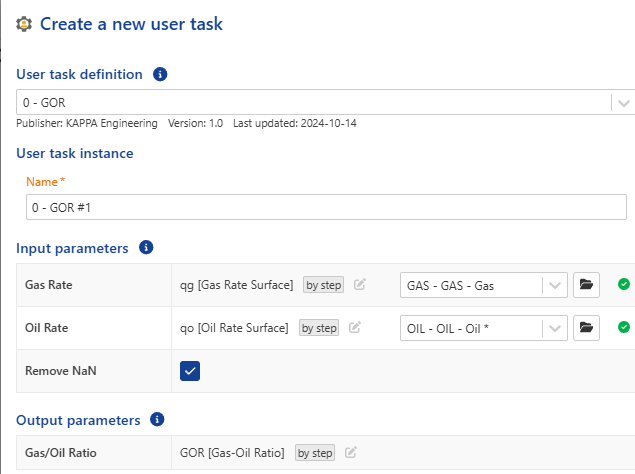 KAPPA-Automate Binding |
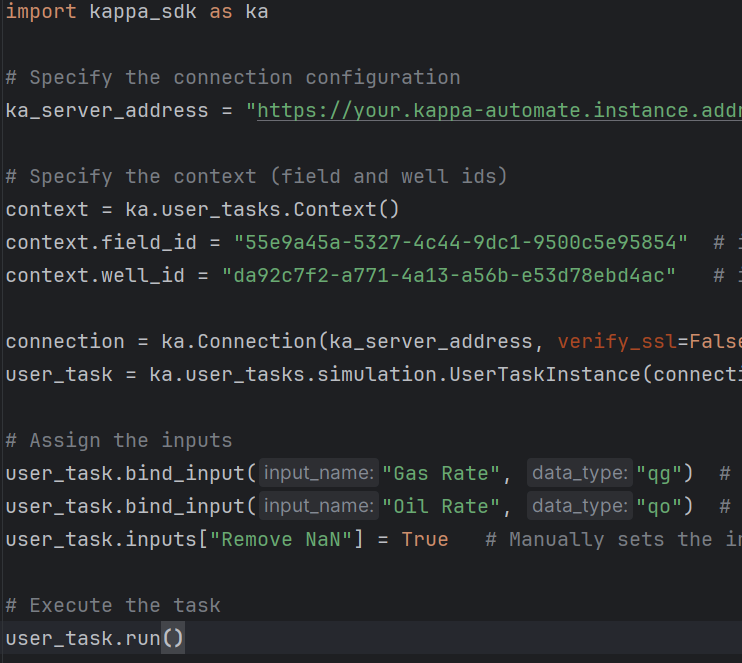 Simulation File |
<user_task_task_name>.yamlcontains the definition of input and output parameters for your user task. This file will be used to do a run-time checking of parameters when making a simulation run of your your task, similar to the way it works in KAPPA-Automate. You will also use the content of this file later to deploy your user task to KAPPA-Automate.<your_user_task_name>.pycontains your actual user task code, that will be later deployed to KAPPA-Automate.

Project Files
Note
When defining the input parameters in the YAML format for dataset inputs, you will need to specify a data-type of Y values of the dataset. Please see the the Data-Types Reference for a complete list of built-in measures.
Note
You can also include a Javascript file to interact with your YAML definition but it will only work when you create a user task through the UI of KAPPA-Automate and not when running in simulation mode.
When running a user task in simulation mode, it will not create a user task under your well. Instead, it will simulate the user task and generate your dataset outputs in a subfolder of the gauge folder within your well. For well property outputs, it will generate a new container exactly like a user task would do.
User task environment#
User task is intended to process 0-n inputs and populate 0-n outputs, optionally storing its internal parameters/state in the context.
In the user task environment you can access the services variable using kappa_sdk.user_tasks.user_task_environment.services in the user task code:
kappa_sdk.Services.contextis astring-key dictionary that allows you to persist values of any serializable data type between the user task executions.kappa_sdk.Services.wellallows you to access the Well where your user task is running.kappa_sdk.Services.fieldallows you to access the Field where your user task is running.kappa_sdk.Services.user_taskallows you to access the user task object itself. In simulation mode it will point to the well since we only replicate a user task execution.kappa_sdk.Services.rest_apiallows you to make calls to KAPPA-Automate through REST API (with post, put, get and delete requests).kappa_sdk.Services.parametersis a container of input and output dictionaries that provide your user task with named input and output values. The following parameter types are supported:dataset(presented as an id of the vector that holds the gauge data)stringdatetimefloatintboolenum(presented as a string value)file(presented as an id of the file)wellproperty(presented as an id of the well property vector that holds the well property history data)wellpropertycontainer(presented as an id of the well property container)
kappa_sdk.Services.data_enumeratorallows you to access data of n gauges using a common time index.kappa_sdk.Services.data_command_serviceallows you to add, replace and delete data to the output gauges.kappa_sdk.Services.data_query_serviceallows you to a read data values and also grab the metadata’s info of the data.kappa_sdk.Services.unit_converterallows you to access the unit converter.kappa_sdk.Services.logallows you to log messages related to your user task.kappa_sdk.Services.schedulerallows you to schedule the next execution of your user task.kappa_sdk.Services.event_publisherallows you to publish events related to your user task.kappa_sdk.Services.redefinitionallows you to handle the redefinition of the user task. This parameter will be None by default unless the user clicks on Redefine in the user task dialog.kappa_sdk.Services.triggerallows you to know what triggered the user task execution. It can be a user, event (data updated) or a schedule trigger. It will also provide the id of the data responsible of the event.
You can have nested functions and classes in your user task code, as natively supported by Python. You can use any Python package in your user task. You will see in the next section how to include any package with your user task. You can also use your own modules, given that you structure them into a package (or several packages). Those packages then should be uploaded to KAPPA-Automate and referenced when deploying a definition of your user task.