The need for speed
We released the first version of our numerical model in 1999.
At that time, a simulation would take anywhere from a few seconds to a few minutes, mainly because we were limited to simple geometries and physics, such as single-phase flow in 2D.
The numerical model embedded in Saphir, Topaze, and Rubis has become increasingly complex over the years.
Today, we can simulate multiphase flow (black-oil, EOS), Kr–Pc hysteresis, thermal effects, complex hydraulic fractures, DFNs, and geometries constrained to corner-point sector grids (Petrel), among others.
Despite continuous efforts to simplify and accelerate problem resolution (multithreading, new linear solvers, dynamic aggregation upscaling), we must face reality:
our gridding approach is designed to build the smallest possible system capable of simulating transient flow in the reservoir, but the resulting models can now take minutes instead of seconds, or even hours, to run.

A brief reference to Moore’s and Huang’s laws
In 1965, Gordon E. Moore, co-founder of Intel, predicted that the number of transistors on a microchip would double every two years, leading to a steady increase in CPU power.
The prediction held true for several decades, but its promise has started to fade over the past 10–15 years due to physical limitations.
In 2018, Jensen Huang, co-founder and CEO of NVIDIA, proposed a GPU counterpart: the performance of GPUs would roughly double every two years.
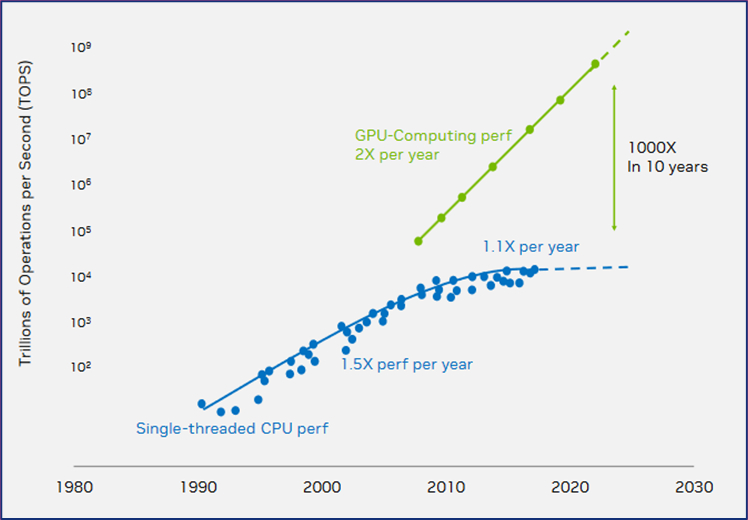
One might argue that these statements are not exactly neutral, and experts may point out that the two ‘laws’ are not driven by the same factors, pure hardware in the case of CPUs, and a combination of hardware and software advances for GPUs.
However, the evidence speaks for itself:
if we want to benefit from the latest computing performance, we must jump on the right GPU train.
For a wide range of reasons, adapting a CPU numerical simulator to GPUs requires a complete rewrite if we want it to be efficient not merely cosmetic.
Furthermore, numerical GPU simulators must be tuned to specific hardware configurations: there is no universal GPU solver, only a series of solver compilations optimized for different graphics card architectures.
Rather than reinventing the wheel and potentially wasting a considerable amount of time and effort for a mediocre result, we decided to collaborate with the Stone Ridge Technology’s ECHELON simulator, the best native GPU reservoir simulator on the market.
What we do now only much, much faster
In KAPPA-Workstation v5.70, Saphir, Topaze, and Rubis users can define their problems, build a Voronoi grid, click ‘simulate’ all as usual, and… run the simulation on ECHELON either installed locally (on a GPU machine) or on a remote, high-performance datacentre, rather than on their local CPU.
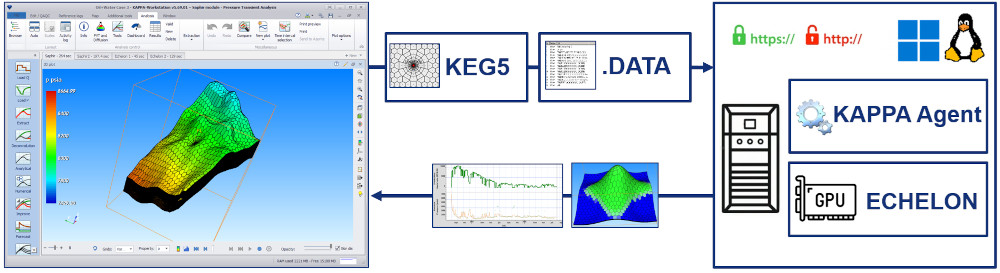
The process is seamless, literally reduced to a single checkbox, and can deliver computing speeds up to 100× faster and, since ECHELON uses the KAPPA Voronoi grid, producing the same results.
Below is a comparison between Rubis CPU (blue) and Rubis–ECHELON (red) across a series of black-oil models.
What is shown here is the time spent in seconds on each time step:
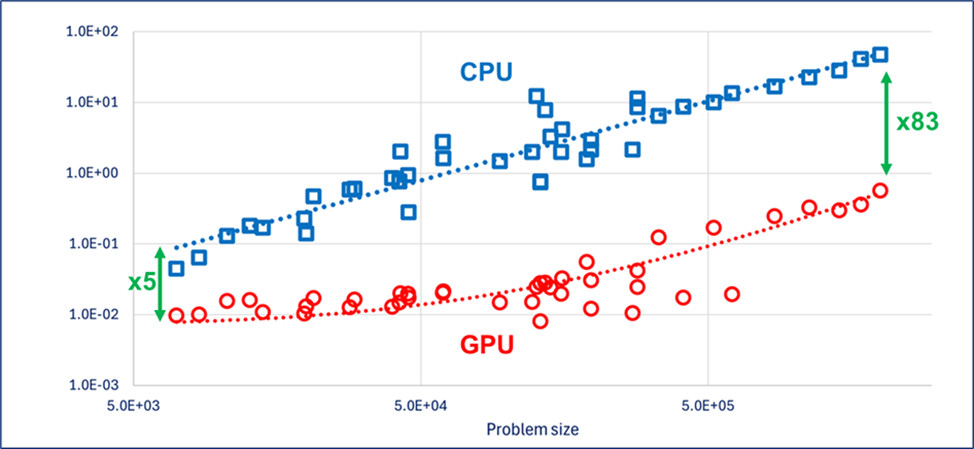
Of course, actual performance will depend on the GPU hardware.
However, KAPPA-Workstation can now take advantage of the latest advances in GPU architecture — we are indeed on the right train.
To learn more about ECHELON :
Visit https://stoneridgetechnology.com/echelon-reservoir-simulation-software/
