Multiwell Load
KAPPA Automate is a dynamic data analysis platform designed to support complex workflows that begin with data ingestion. In scenarios involving unconventional resources, workflows often require processing data from hundreds or thousands of wells. The single-well ingestion becomes inefficient and impractical at this scale. To address this, KAPPA-Automate provides the Multiwell Load Workflow, a scalable solution for bulk data import. This workflow is part of the external data service which uses a plugin-based architecture, where each plugin acts as a bridge between KAPPA-Automate and your organizations external data source (e.g. SQL Server, Snowflake, Oracle, PI historians, cloud data lakes). This ensures seamless integration of data from diverse technologies into KAPPA-Automates data model without modifying the core system. The workflow handles the data retrieval and transformation, while KAPPA-Automates services handle digestion and synchronization.
Multiwell Load Process
The multiwell load workflow works in coordination with the mirroring services. There are three stages to the multiwell load workflow. Each created multiwell load will activate the workflow on a user-defined schedule and will update well, well properties, and gauge information on each execution of the workflow.
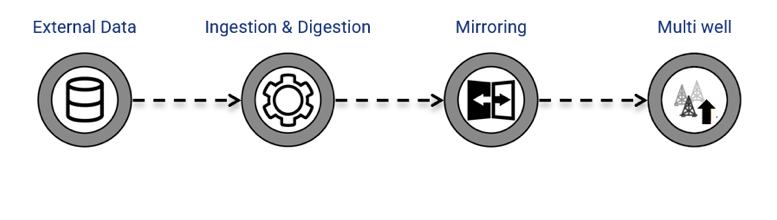
Ingestion: The multiwell load plugin connects to external data sources, retrieves well and gauge information, and converts it into KAPPA’s standardized internal format. Units are aligned to SI, timestamps normalized to UTC, and data is temporarily stored in the internal load repository for downstream processing.
Digestion: The system imports data from the internal repository into KAPPA’s data model, creating or updating wells, properties, and gauges while ensuring data consistency. Digestion runs asynchronously, allowing multiple ingestion jobs to execute in parallel.
Mirroring: After digestion, gauges are configured for periodic synchronization with external databases, maintaining up-to-date time-series data without requiring full reloads. Mirroring uses the identifiers and tags generated during ingestion and applies uniformly to all gauges.