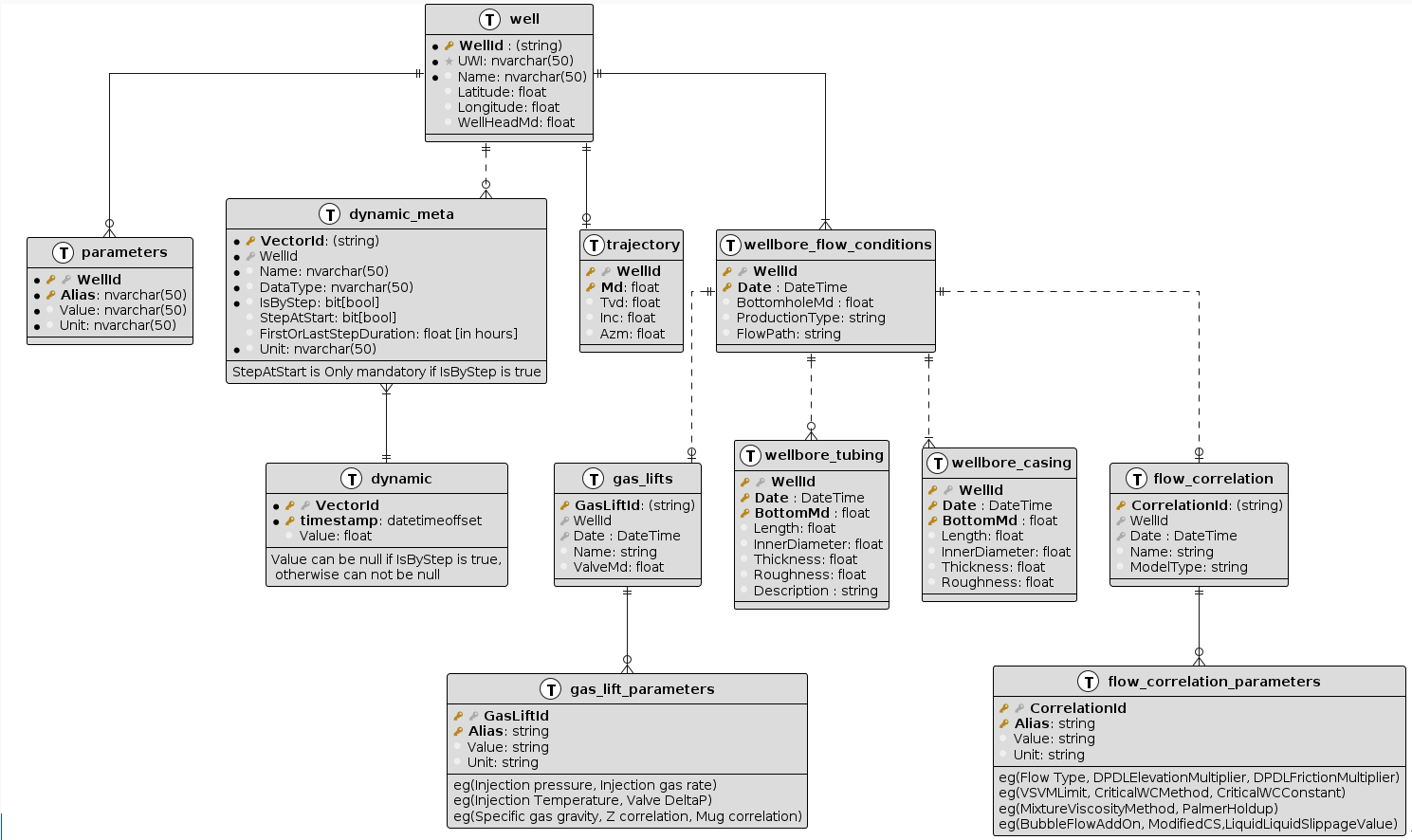
Multiwell Load External Plugins and Type 2 Database Schema
For multiwell data loads, external data plugins are responsible exclusively for the ingestion phase of the workflow. These plugins act as the interface between KAPPA-Automate and external source systems, extracting and transforming data so that it conforms to the KAPPA-Automate data model.
To achieve this, a multiwell load plugin performs the following key operations:
Establishing and managing connections to the source system
Handling authentication and authorization
Querying source data and retrieving metadata and measurements
Defining well-level properties
Loading well and gauge metadata in a consistent, structured manner
All connection and retrieval logic is encapsulated within the plugin, ensuring that KAPPA-Automate remains independent of external database schemas, query languages, and communication protocols. This allows changes to source systems to be handled atthe plugin level without impacting the core K-A platform.
KAPPA-Automate currently supports multiwell load plugins for the following source systems:
SQL Server
Snowflake
IHS298
Excel
These plugins provide a consistent ingestion experience across all supported data sources.
Type 2 Database Schema (KAPPA SQL)
The Type 2 database schema (KAPPA SQL) is the standard schema used for multiwell data ingestion in KAPPA-Automate. It is designed to support scalable multiwell data structures and is aligned with the KAPPA-Automate data model.
This schema provides a consistent structure for integrating external SQL-based data sources, enabling efficient data ingestion, normalization, and validation.
The KAPPA SQL schema supports:
Static data, such as well metadata and configuration information
Dynamic data, such as time-series measurements and other evolving datasets
This unified approach ensures flexibility, scalability, and consistency across all multiwell ingestion workflows.