Incremental RTA (iRTA)
The iRTA workflow starts with a Topaze document containing a user-generated analysis. The workflow can then proceed automatically from a pressure and possible rate feeds. When both data sets are available the options are to extract and regenerate the model, or to generate and improve — on the complete duration. When only pressure is available, rates will be generated in what is called the ‘Virtual meter’ mode.
iRTA Workflow Types
There are four types of iRTA workflows available:
Extraction only: This is the only available option if the selected ‘RTA document’ does not contain a model. The data will be sent to the RTA µ-service which will perform the extraction.
Extraction with model: In addition to Extraction only explained above, the model in the RTA document is extended up to the end of production data. If the seed document contains a model with a forecast of duration dt, the model simulation will continue to end of production data + dt.
Extraction with model + improve: In addition to Extraction with model explained above, if this option is selected, an improve strategy is requested by the user at the time of iRTA creation. The user can specify what model parameters to improve on and their ranges and set the improve targets and their weights. During execution, after the model has been extended to the end of the processed data, an improve of the history plot is performed.
Virtual Metering: This option is available only when the seed Topaze document has a q(p) model. If the seed document contains a model with a forecast of duration dt, the model simulation will continue to end of pressure data + dt.
Note
The forecast option is available for iRTA seed files with a model. This feature is enabled when the 'Model' or 'Model + Improve' workflow type is selected, and the forecast type (constant pressure or rate) depends on the seed model.
Gauge Loading Strategy
When the workflow is triggered, the gauge data in the corresponding Topaze needs to be updated first. Two choices are offered:
Append: Pressure and rate data are appended to existing gauges.
Load: Existing gauges are replaced with fresh gauges, containing all the data.
Duration of data to analyze
iRTA execution is triggered by production data updates, which may occur at high frequency. To avoid unnecessary executions:
Users can define a minimum duration of data to analyze (default: 120 days).
iRTA runs only when this duration is reached.
Improve only on new data
It is possible to improve on new data only using the option ‘improve only in new data’, which only uses the new data as target to improve the model.
Document Update Strategy
If the Workflow type is set to Extraction only, Extraction with model or Extraction with model + improve, upon execution, the iRTA workflow will create a new Topaze document containing data from the start of production history up to the end of the extraction.
If the Workflow type is set to Virtual Metering, the iRTA workflow keeps updating the same Topaze document.
Viewing iRTA Results
When an iRTA is first launched, it will create a new container under Well properties node in the field hierarchy, named Container for <iRTA Name>.
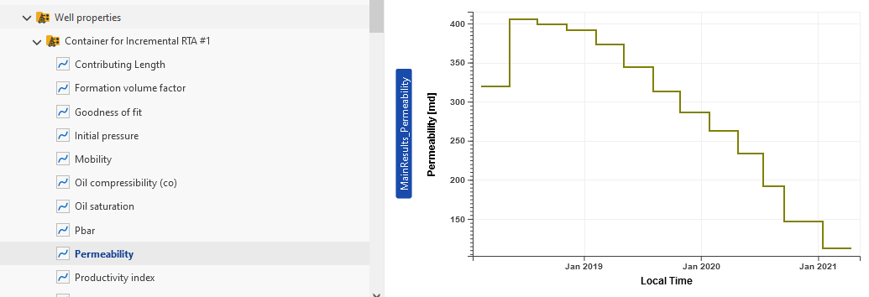
A new folder called Workflows will also be created in the field hierarchy, with the iRTA and any files created by this iRTA listed there. Depending on the selection of output gauges when creating the iRTA, the computed rate, cumulative, and possibly pressure and productivity index are written back under the parent well:
Computed channels are generated by:
Extracting a segment of data of length n (the duration of data to analyze) from each output document.
Combining these segments to produce the computed rates.
If only one output document exists, the computed channel is simply a copy of the simulated channel in Topaze.
 |
An important assumption of iRTA is that the well is not subject to nearby well interference.
One can run several workflows in parallel and compare them.
It is also possible to copy from in iRTA container into the Master container. If Replicate results to Master flag was enabled when creating the iRTA, this will be done automatically for all shut-ins being processed by the iRTA task.
Alternatively, users can selectively replicate results for some analyses only to the Master well properties container (see [Result Replication into Master Well Properties] for more details).